
Originally published in the AESP Energy Intel Magazine Q2 2024 (56-60).
Artificial intelligence models are key components to any effort to decarbonize and enhance the sustainability of the grid. There is simply too much data from too many sources. We need computers to recognize patterns, predict, and make decisions to help us answer questions such as: Which energy consumers are most likely to engage with certain interventions? Which assets should we deploy to manage the load demands in real time? But these efforts, as is true of any domain reliant on machine learning and Al, will always be limited by the underlying quality, quantity, and access of the data. To put it simply, a model is only as good as its data.
In this article we will discuss the changes we have been making at our company, Uplight, to update all aspects of our “data culture” including architecture, technology, and team structure – all in service of improving our data and related processes. This is not to suggest that we have all the answers. Our effort is still very much a work in progress, and we anticipate a need to continue iterating and evolving. We’ll talk about where we were and the gaps we saw, as well as the initial solutions we are implementing all to help others think through their own energy data transformations. Ultimately, with these data transformations, we aim to accelerate the development of analytic solutions designed to achieve our collective goals for the grid.
For those unfamiliar with Uplight, our mission is to tackle the decarbonization of the grid while simultaneously ensuring its longevity. We execute our mission by building solutions and partnerships with energy utilities and companies at the grid edge (think: smart device manufacturers, etc.). These solutions and partnerships aim to reduce the overall burden on the grid while also enabling the flexibility required to meet the increasing demand that electrification places on existing infrastructure. At the heart of the solution are people – specifically, energy consumers. Our objective is to meet energy consumers where they are at and empower them to take action. We do this by providing personalized education around energy use, matching eligible customers to relevant programs and rebates, driving adoption of energy-efficient products, and connecting, managing, and optimizing distributed energy resources to integrate and orchestrate peak demand and day-to-day generation. At the core of each of these engagements is data – and the insights we derive and produce from it.
To offer solutions to our customers now and as needs evolve, we anticipate (at least) three things must be true:
- Our data must be high quality
- Our teams must understand how to use the data to develop our capabilities
- All analytic development must be as efficient as possible
Over the last few years, our engineering and product leadership realized we had some serious gaps when it came to these three tenets and we decided it was time to get curious and experiment to fill them.
Breaking Down Data Silos
We believe data quality is more than simply “correctness.” Quality data must be accurate, of course, but also accessible, joinable, and discoverable. A pattern we quickly realized (in large part because Uplight is a company made up of eight legacy companies) is that data sourced from different systems with different architectures tends to stay siloed, which significantly limits the value of that data. One example of how this manifested for Uplight was an absence of a common set of identifiers in all existing datasets, which meant joining data was challenging at a minimum, and impossible in some cases. We realized that our siloed architecture limited the quality of our data and, therefore, the quality of our solutions. Establishing a vision and strategy for achieving a common and unified data architecture – one in which data could be joined, governed, and discovered quickly and efficiently – became a major priority. Over the last year, we started executing this vision with three related efforts.
The first effort was changing our processes. Quarterly planning tended to be just as siloed as our data, with roadmaps developed within each product rather than across all products. This meant it was easy to miss the reality that data from one product could and should be used to help enrich data from other products. We raised our heads and started to have more conversations across work streams. These conversations enabled us to prioritize bringing data together and organizing it more cohesively.
More effective cross-product planning allowed us the space and capacity to start the second effort: establishing a lakehouse architecture (see graphic for an overview of what this looks like). A data lakehouse, a term coined by Databricks, is an architecture that brings together data lakes, data warehouses, and machine learning under one umbrella to allow for streamlined data discoverability, lineage, governance, and democratization. Importantly, the lakehouse allows us to define how data should be organized regardless of the source. Now, teams can find the data they need to use. We have mitigated the risk of data discrepancies by limiting where business logic is applied. We have implemented access patterns and restrictions that protect and enforce data privacy and sovereignty standards, and we have set expectations that teams can and should source data from the lakehouse as well as publish any data their products create in the lakehouse. With this new architecture, the silos that used to exist because of historical reasons are no longer the default.
The third effort, enabled by our new architecture, was to define an enterprise view of the core data we obtain from all our various sources. By “enterprise view,” we mean streamlining data to create an easily consumable version for internal and external users. This proved especially critical for utility data. Before this enterprise view, using utility data required a decent amount of cognitive effort. This is because each utility’s data has their own quirks – for example, move-outs can look different or account identifiers might be reused over time. Each team that wanted to use utility data needed to understand these quirks. Now, we’ve created an enterprise view by transforming each utility into a common utility data model. Only the teams involved in ingesting the utility data are required to know all the idiosyncrasies, so everyone else can focus on leveraging it in service of our solutions.
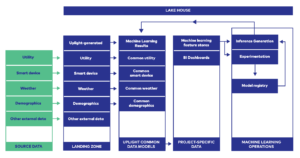
Democratizing Modeling Development
We also realized that silos existed within the structure of our teams, specifically as it related to knowledge of how to build analytic capabilities. Model development tended to be the domain of only a few teams, but model-based insights were required in almost all the products that every team at Uplight supported. These siloes had inadvertently created a culture where the engineering teams that owned analytic services did not feel empowered to understand the basics of their capabilities, including what data was required, if the results made sense, and how to monitor and improve the service over time. Any questions about “a model” went through people with a job title like Data Scientist. Given that we hire smart, motivated, and mission-aligned employees, we realized that the data democratization that would result from breaking down data silos and creating a unified data architecture could expand to encompass model development democratization as well. Empowering engineers across the organization to feel comfortable actively participating in the machine learning lifecycle is not an easy task. We identified two distinct efforts that would be necessary to minimize this friction as much as possible.
First, we needed a way to efficiently and scalably give the teams building analytics services access to data science specific knowledge and skill sets. We previously staffed engineering teams that built model-based capabilities with embedded data scientists. As the company grew – and with it, our portfolio – we experienced issues staffing the work we wanted to prioritize, and friction with the natural flow of true data science work. Initial model development benefits from the work of trained data scientists, as does model iteration and improvement. Deploying and maintaining a service that contains a model, however, involves solving challenges like scalability and cost optimization, which are problems well suited for data and/or software engineers.
A fully embedded model quickly became inefficient for us. We noticed a pattern of data scientists taking on engineering work instead of focusing on model development, and engineers waiting for data science capacity. Our solution was a pivot to a consulting model. We separated some of our data scientists into their own team and began allocating work based on the roadmaps of engineering teams across the business. Data scientists will embed for a quarter or two on an engineering team to help with model development and iteration, and then they move to a different team once the work switches to implementation and maintenance of the modeling service. This approach enabled us to more flexibly support the areas of the business where we are looking to invest.
In addition to being intentional about where and how our data scientists were working, we also wanted to reduce the implementation burden on engineering teams to stand up and maintain an analytic service so we could release more, more frequently, and with higher quality. Golden paths – establishing reusable templates and standards to reduce cognitive load during development and drive consistency across solutions – are key here. We had a team of data engineers modify their team charter to develop and steward Machine Learning Operations (MLOps) for all of Uplight. Through their work, golden paths for all aspects of the machine learning lifecycle are being actively developed. Engineering teams do not need to reinvent the wheel every time they are asked to develop an analytic service, thus reducing the overall scope and complexity of each effort.

Efficiency as a Value Multiplier (Plus Cost Savings!)
If data is no longer siloed, and engineering teams are equipped to develop and maintain analytic, machine learning, and Al services (utilizing golden paths and consulting with data scientists as needed), we can meet the changing needs of our customers and charter much more efficiently. If a product manager over one part of our solutions wants to prototype a new model, for example, they can carve out room on their team’s roadmap rather than needing to go through a centralized team. We recently saw this in real life: We had a bill comparison model that was specific for one utility, but we understood the value of this for all of our customers. An engineering team had capacity but had never built or modified an analytic service before. They were able to leverage our data scientists and the MLOps infrastructure to expand the service for all utilities, while simplifying and standardizing the implementation so maintenance and ownership will be easier.
In addition to expanding our ability to help decarbonize the grid through our solutions, being more efficient also means that we are seeing cost savings. Redundant data is now minimized, which has reduced our cloud costs. Teams can build new services more efficiently, also cutting our roadmap and development costs.
But perhaps even more important than cost savings (depending on who you ask), we are seeing shifts in the overall culture around our data and modeling capabilities. Teams are leaning into full ownership of their services and more folks can speak to what our data is, where and how to use it, and how our solutions enable our company’s goal of enabling decarbonization.
Next Steps
So, are we done? Not even close. As we noted at the beginning, we are approaching all of this as an experiment, and we expect that we will continue to iterate and evolve. The goal is not perfection but rather to keep improving. The landscape of energy analytics will continue to change as new devices come online, electrification increases, and energy consumers require new and different ways of engaging with their energy use. While we may not have all the answers yet, we feel confident that we have made impactful progress and are excited to keep moving forward – delivering solutions to our internal teams, utility and ecosystem partners, and energy consumers.


